Deploy Snipe It with Kubernetes
In the previous post, we spoke about Snipe It and how to deploy it with docker. As is a simple product let’s introduce how to deploy this simple tool with Kubernetes.
First let’s introduce Kubernetes.
Kubernetes is an open-source platform for managing containerized workloads and services. Kubernetes manage containers system resiliently. It takes care of scaling and failover for your application, provides deployment patterns, and more.
Kubernetes works with several components:
Kubernetes is deployed with a Cluster who consists of a set of worker machines, called nodes, that run containerized applications. Every cluster has at least one worker node.
The worker node(s) host the Pods that are the components of the application workload. The control plane manages the worker nodes and the Pods in the cluster. In production environments, the control plane usually runs across multiple computers and a cluster usually runs multiple nodes, providing fault-tolerance and high availability.

You will find all the informations needed to https://kubernetes.io/docs/concepts/overview/what-is-kubernetes/
Now we have more knowledge on Kubernetes let’s see how to deploy snipe-it on k8s.
Snipe It docker installation is available on https://snipe-it.readme.io/docs/docker. We need two containers Mysql and Snipe It to let the app work.
That means we will have running pods for Snipe and Mysql.
Let’s create a folder app with all the components files, the first one will be for MySQL.
The file mariadb_deployments.yml will create two components for the database.
First one is Deployment, the deployment provides declarative updates for Pods. The second one is PersistentVolumeClaim, is a request for storage by a user. It is similar to a Pod. Pods consume node resources and PVCs consume PV resources. Pods can request specific levels of resources (CPU and Memory). Claims can request specific size and access modes (e.g., they can be mounted ReadWriteOnce, ReadOnlyMany or ReadWriteMany).
Let’s take a look to the file
apiVersion: apps/v1
kind: Deployment
metadata:
name: snipedb
labels:
app: snipe
spec:
selector:
matchLabels:
app: snipe
tier: snipedb
strategy:
type: Recreate
template:
metadata:
labels:
app: snipe
tier: snipedb
spec:
containers:
- name: snipedb
image: mariadb
resources:
limits:
memory: 512Mi
cpu: "1"
requests:
memory: 256Mi
cpu: "0.2"
ports:
- containerPort: 3306
volumeMounts:
- name: snipedb-pvolume
mountPath: /var/lib/snipeit
env:
- name: MYSQL_ROOT_PASSWORD
value: "mysql_root_password"
- name: MYSQL_DATABASE
value: "snipe"
- name: MYSQL_USER
value: "snipeit"
- name: MYSQL_PASSWORD
value: "mysql_password"
volumes:
- name: snipedb-pvolume
persistentVolumeClaim:
claimName: snipedb-pvolume
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: snipedb-pvolume
labels:
app: snipedb
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5GiThe Deployment Metadata name is snipedb and it’s tagged with the labels app snipe. Labels are key/value pairs that are attached to objects, such as pods. Labels can be used to organize and to select subsets of objects.
The .spec.strategy.type==Recreate will kill all the previous pods before create new.
in .template.spec we will retrieve all the configs for the pods, we create the volume snipedb-pvolume who use the PersistantVolumeClaim snipedb-pvolume. A volume snipedb-pvolume has been created in .template.spec.containers.volumeMounts this volume use the declarated volume in .template.spec.volumes
The persistentVolumClaim .spec.accessModes has been setup in ReadWriteOnce. That means the volume can be mounted as read-write by a single node. Multiple pods under same nodes can access to Volume.
As the mysql we will create a deployment and a PersistantVolumeClaim for the snipe app.
Now let’s check the snipe_deployments.yml file
apiVersion: apps/v1
kind: Deployment
metadata:
name: snipe
spec:
selector:
matchLabels:
app: snipe
tier: frontend
strategy:
type: Recreate
template:
metadata:
labels:
app: snipe
tier: frontend
spec:
containers:
- name: snipe
image: snipe/snipe-it:latest
livenessProbe:
httpGet:
port: 80
resources:
limits:
memory: 512Mi
cpu: "1"
requests:
memory: 256Mi
cpu: "0.2"
ports:
- containerPort: 80
volumeMounts:
- name: snipe-pvolume
mountPath: /var/lib/snipeit
env:
- name: APP_ENV
value: "preproduction"
- name: APP_DEBUG
value: "true"
- name: APP_KEY
value: "base64:D5oGA+zhFSVA3VwuoZoQ21RAcwBtJv/RGiqOcZ7BUvI="
- name: APP_URL
value: "http://127.0.0.1:9000"
- name: APP_TIMEZONE
value: "Europe/Paris"
- name: APP_LOCALE
value: "en"
- name: DB_CONNECTION
value: "mysql"
- name: DB_HOST
value: "snipedb"
- name: DB_DATABASE
value: "snipe"
- name: DB_USERNAME
value: "snipeit"
- name: DB_PASSWORD
value: ""
- name: DB_PORT
value: "3306"
- name: MAIL_PORT_587_TCP_ADDR
value: "smtp.gmail.com"
- name: MAIL_PORT_587_TCP_PORT
value: "587"
- name: MAIL_ENV_FROM_ADDR
value: "mail@domain.com"
- name: MAIL_ENV_FROM_NAME
value: ""
- name: MAIL_ENV_ENCRYPTION
value: "tls"
- name: MAIL_ENV_USERNAME
value: "mail@domain.com"
- name: MAIL_ENV_PASSWORD
value: ""
volumes:
- name: snipe-pvolume
persistentVolumeClaim:
claimName: snipe-pvolume
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: snipe-pvolume
labels:
app: snipe
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 5Gi
The container image snipe/snipe-it:latest it’s used.
.spec.container.livenessprobe it’s used to know when to restart a container.
With snipe_deployments.yml and mariadb_deployment.yml we have the Deployments ready.
We have now to deploy Services to expose an application running on a set of Pods as a network service.
The snipe_services.yml will be used to expose Snipe app port 80 and databse 3306 port.
apiVersion: v1
kind: Service
metadata:
name: snipe-entrypoint
labels:
app: snipe
spec:
ports:
- port: 80
selector:
app: snipe
tier: frontend
clusterIP: None
---
apiVersion: v1
kind: Service
metadata:
name: snipedb
labels:
app: snipedb
spec:
ports:
- port: 3306
selector:
app: snipe
tier: snipedb
clusterIP: None
Now we should have a folder with three files snipe_deployments.yml, mariadb_deployments.yml and snipe_services.yml.
To generate the application run from command line the command
kubectl apply -f ./this command will apply all the files and generate all the components.
Finally add a forward port to the service with the command
kubectl port-forward service/snipe-entrypoint 9000:80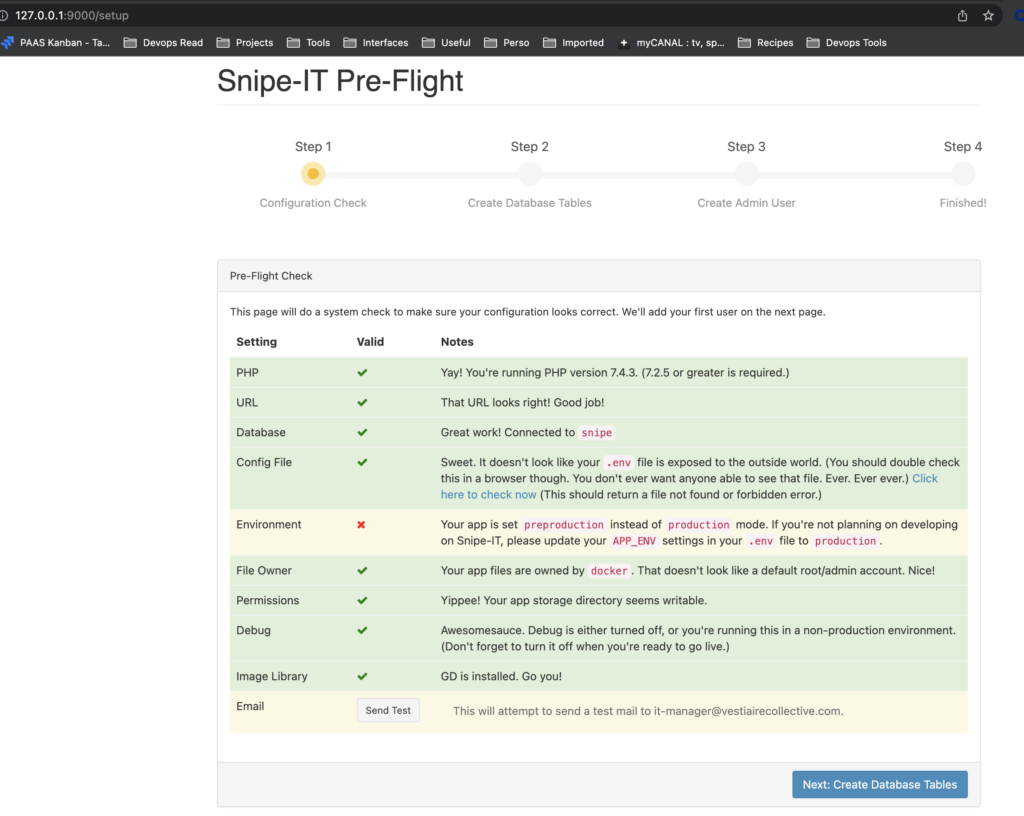
Use command kubectl-get, kubectl describe for have more information on the running apps.
https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands